DeepEyes是什么
DeepEyes 是小红书团队和西安交通大学联合推出的多模态深度思考模型。基于端到端强化学习,实现类似 OpenAI o3 的“用图思考”能力,无需依赖监督微调(SFT)。DeepEyes 在推理过程中动态调用图像工具,如裁剪和缩放,增强对细节的感知与理解。模型在视觉推理基准测试 V* Bench 上准确率高达 90.1%,展现出强大的视觉搜索和多模态推理能力。DeepEyes 具备出色的图像定位能力,能有效减少幻觉现象,提升模型的可靠性和泛化能力。
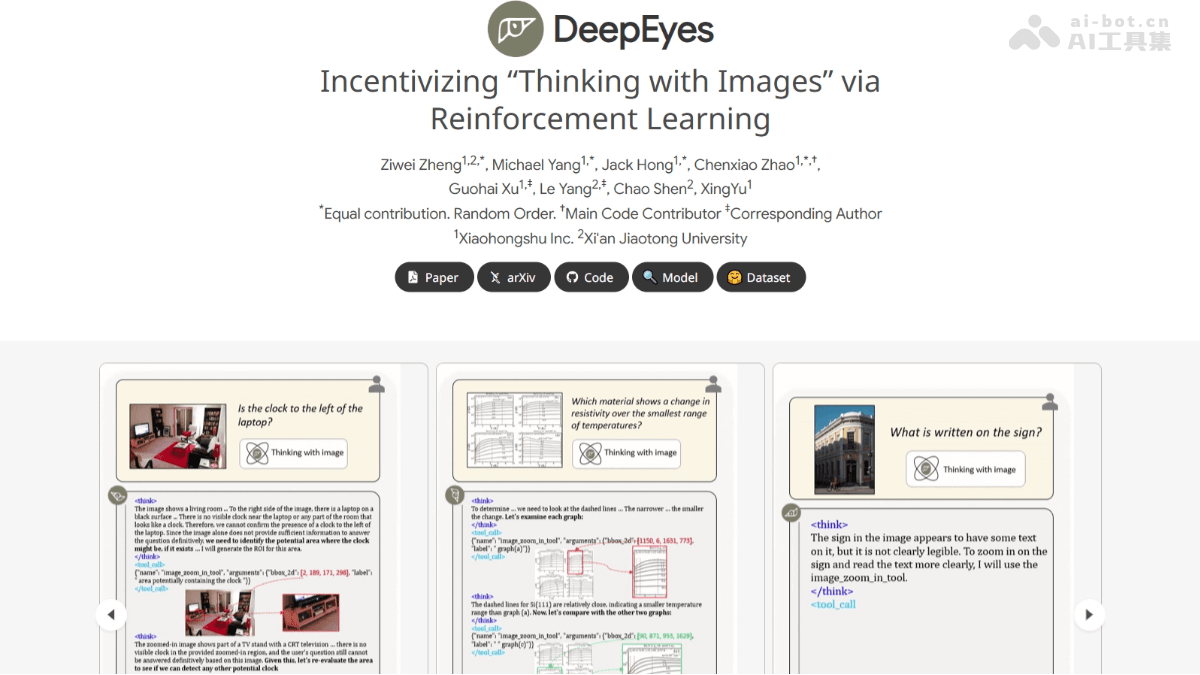
DeepEyes的主要功能
- 用图思考:直接将图像融入推理过程,不仅“看图”,还能“用图思考”,在推理过程中动态调用图像信息,增强对细节的感知与理解。
- 视觉搜索:在高分辨率图像中快速定位小物体或模糊区域,基于裁剪和缩放工具进行详细分析,显著提升搜索准确率。
- 幻觉缓解:基于聚焦图像细节,减少模型在生成回答时可能出现的幻觉现象,提升回答的准确性和可靠性。
- 多模态推理:在视觉和文本推理之间实现无缝融合,提升模型在复杂任务中的推理能力。
- 动态工具调用:模型能自主决定何时调用图像工具,如裁剪、缩放等,无需外部工具支持,实现更高效、更准确的推理。
DeepEyes的技术原理
- 端到端强化学习:DeepEyes 用端到端强化学习(RL)训练模型,无需冷启动监督微调(SFT)。基于奖励信号直接优化模型的行为,自主学习如何在推理过程中有效利用图像信息。奖励函数包括准确率奖励、格式奖励和条件工具奖励,确保模型在正确回答问题的同时,高效地使用图像工具。
- 交错多模态思维链(iMCoT):DeepEyes 引入交错多模态思维链(Interleaved Multimodal Chain-of-Thought, iMCoT),支持模型在推理过程中动态地交替使用视觉和文本信息。模型在每一步推理中决定是否需要进一步的视觉信息,基于生成边界框坐标裁剪图像中的关键区域,将区域重新输入模型,作为新的视觉证据。
- 工具使用导向的数据选择:为更好地激励模型的工具使用行为,基于工具使用导向的数据选择机制。训练数据经过精心筛选,确保样本有效促进模型的工具调用能力。数据集包括高分辨率图像、图表数据和推理数据,覆盖多种任务类型,提升模型的泛化能力。
- 动态工具调用行为:在训练过程中,模型的工具调用行为经历三个阶段:初始探索、积极使用和高效利用。模型从最初的随机尝试逐渐发展到高效、准确地调用工具,最终实现与人类类似的视觉推理过程。
- 多模态融合:DeepEyes 基于将视觉和文本信息深度融合,构建一个统一的推理框架。融合提升了模型在视觉任务中的表现,增强了在多模态任务中的整体性能。
DeepEyes的项目地址
- 项目官网:https://visual-agent.github.io/
- GitHub仓库:https://github.com/Visual-Agent/DeepEyes
- HuggingFace模型库:https://huggingface.co/ChenShawn/DeepEyes
- arXiv技术论文:https://arxiv.org/pdf/2505.14362
DeepEyes的应用场景
- 教育辅导:解析试卷中的图表和几何图形,为学生提供详细的解题步骤,提升学习效率。
- 医疗影像:分析医学影像,辅助医生进行诊断,提高诊断的准确性和效率。
- 智能交通:实时分析路况图像,辅助自动驾驶系统做出更准确的决策,提升交通安全。
- 安防监控:分析监控视频,识别异常行为,增强公共安全和犯罪预防能力。
- 工业制造:在生产线上进行质量检测和设备故障预测,提高生产效率并降低维护成本。
相关文章
AI应用官网收录了国内外数百个AI工具,该导航网站包括AI写作工具、AI图像生成、AI视频制作、AI音频转录、AI辅助编程、AI音乐生成、AI绘画设计、AI对话聊天等AI应用大全,以及AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务 Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。PS:本站数据由软件自动抓取于互联网公开信息,如有侵权,请联系qq1982182219删除