MobileCLIP2是什么
MobileCLIP2是苹果公司研究人员推出的高效端侧多模态模型,是MobileCLIP的升级版本。在多模态强化训练方面进行了优化,通过在DFN数据集上训练性能更优的CLIP教师模型集成和改进的图文生成器教师模型,进一步提升了模型性能。MobileCLIP2在零样本分类任务上表现出色,例如在ImageNet-1k零样本分类任务中,准确率较MobileCLIP-B提升了2.2%。MobileCLIP2-S4在保持与SigLIP-SO400M/14相当的性能的同时,模型规模更小,推理延迟更低。在多种下游任务中也展现了良好的性能,包括视觉语言模型评估和密集预测任务等。MobileCLIP2适用于图像检索、内容审核和智能相册等多种应用场景,能基于文本描述检索相关图像、进行图文一致性检查以及自动图像分类等。
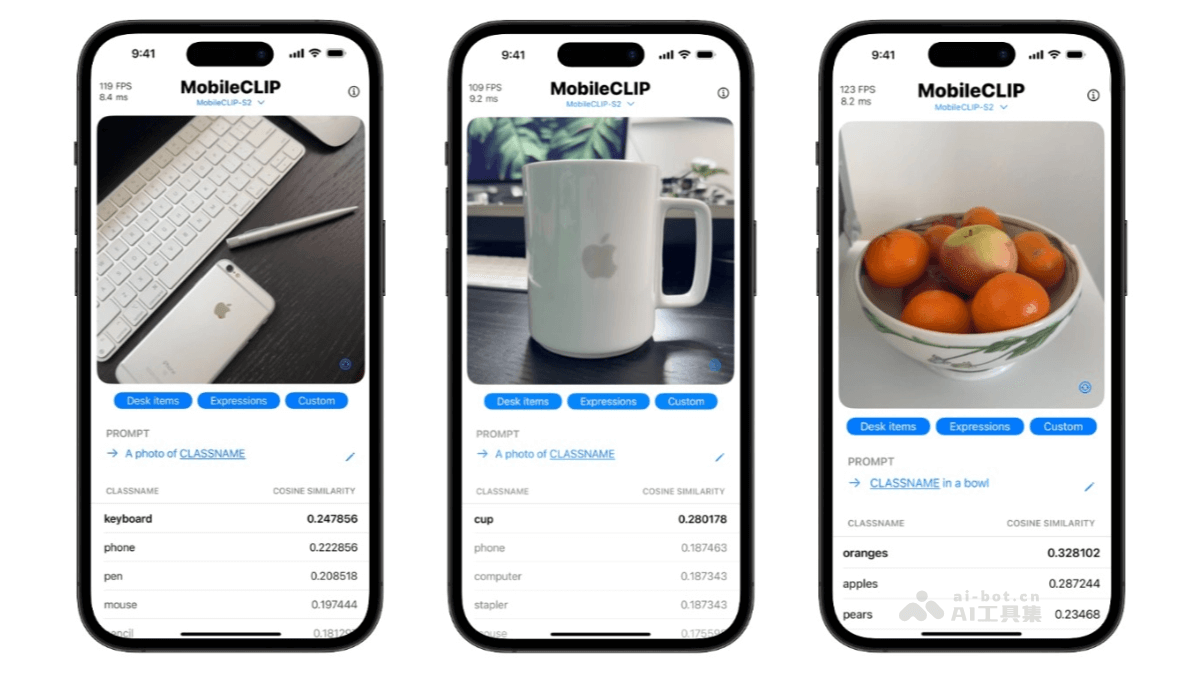
MobileCLIP2的主要功能
-
零样本图像分类:利用预训练的多模态特征,直接对图像进行分类,无需额外训练数据,可快速适应新任务。
-
文本到图像检索:根据输入的文本描述,从图像库中检索出与之最相关的图像,实现精准的图像搜索。
-
图像到文本生成:基于输入图像生成描述性的文本,为图像添加合适的标题或描述,辅助内容理解和创作。
-
图文一致性判断:评估图像与文本描述之间的匹配度,可用于内容审核、智能相册分类等场景,确保图文相符。
-
多模态特征提取:为图像和文本提取高质量的多模态特征,支持下游任务如图像分类、目标检测、语义分割等,提升模型性能。
MobileCLIP2的技术原理
-
多模态强化训练:通过优化CLIP教师模型集成和图文生成器教师模型的训练,提升模型对图像和文本的联合理解能力,增强多模态特征的表达。
-
对比知识蒸馏:采用对比知识蒸馏技术,从大型教师模型中提取关键信息,传递给小型学生模型,实现模型性能与效率的平衡。
-
温度调节优化:在对比知识蒸馏中引入温度调节机制,优化模型的训练过程,提高模型对不同模态数据的适应性和泛化能力。
-
合成文本生成:利用改进的图文生成器生成高质量的合成文本,丰富训练数据,提升模型对文本多样性的理解和生成能力。
-
高效模型架构:设计轻量级的模型架构,如MobileCLIP2-B和MobileCLIP2-S4,在保持高性能的同时,显著降低模型的计算复杂度和推理延迟,适合端侧部署。
-
微调与优化:在多样且高质量的图像-文本数据集上进行微调,进一步提升模型在特定任务上的表现,增强模型的实用性和适应性。
MobileCLIP2的项目地址
- Github仓库:https://github.com/apple/ml-mobileclip
- HuggingFace模型库:https://huggingface.co/collections/apple/mobileclip2-68ac947dcb035c54bcd20c47
MobileCLIP2的应用场景
-
移动应用:可用于增强现实应用、个人助理、实时照片分类等,使手机能在本地完成数据处理,无需将数据发送到云端。
-
边缘计算:适合带宽和处理能力有限的边缘计算环境,如无人机、机器人和远程传感器等设备,可利用模型执行视觉识别任务,实现实时决策。
-
物联网设备:可集成到物联网(IoT)设备中,如安全摄像头或智能家居助手,使这些系统能执行本地视觉识别,具有隐私保护、低延迟和在互联网连接不稳定环境中运行的优势。
-
图像分类:作为轻量级的零样本图像分类解决方案,即使模型没有见过某类图像,只要提供文字类别标签,也能判断图片属于哪个类别。
-
特征提取:作为特征提取器,为图像和文本提取高质量的多模态特征,可作为下游任务的输入,如扩散模型(如Stable Diffusion)和多模态大语言模型(如LLaVA)。
相关文章
AI应用官网收录了国内外数百个AI工具,该导航网站包括AI写作工具、AI图像生成、AI视频制作、AI音频转录、AI辅助编程、AI音乐生成、AI绘画设计、AI对话聊天等AI应用大全,以及AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务 Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。PS:本站数据由软件自动抓取于互联网公开信息,如有侵权,请联系qq1982182219删除