OmniAvatar是什么
OmniAvatar是浙江大学和阿里巴巴集团共同推出的音频驱动全身视频生成模型。模型根据输入的音频和文本提示,生成自然、逼真的全身动画视频,人物动作与音频完美同步,表情丰富。模型基于像素级多级音频嵌入策略和LoRA训练方法,有效提升唇部同步精度和全身动作的自然度,支持人物与物体交互、背景控制和情绪控制等功能,广泛应用在播客、互动视频、虚拟场景等多种领域。
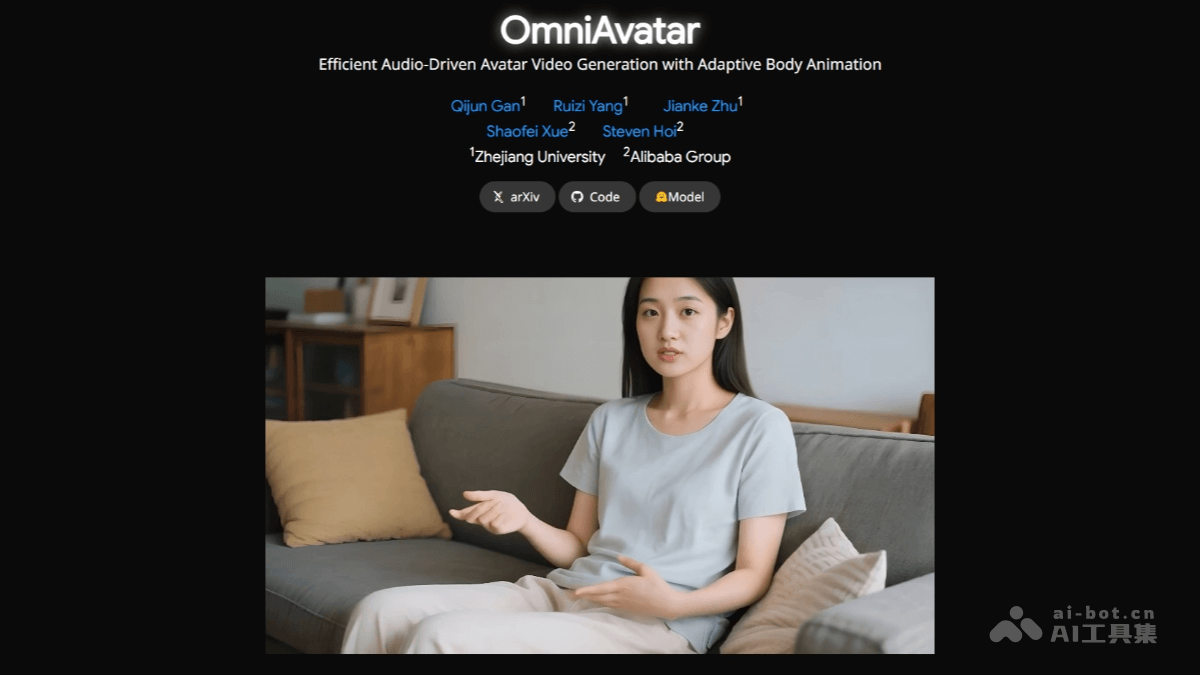
OmniAvatar的主要功能
- 自然唇部同步:能生成与音频完美同步的唇部动作,在复杂场景下保持高度准确性。
- 全身动画生成:支持生成自然流畅的全身动作,让动画更加生动逼真。
- 文本控制:基于文本提示精确控制视频内容,包括人物动作、背景、情绪等,实现高度定制化的视频生成。
- 人物与物体交互:支持生成人物与周围物体互动的场景,如拿起物品、操作设备等,拓展了应用范围。
- 背景控制:根据文本提示改变背景,适应各种不同的场景需求。
- 情绪控制:基于文本提示控制人物的情绪表达,如快乐、悲伤、愤怒等,增强视频的表现力。
OmniAvatar的技术原理
- 像素级多级音频嵌入策略:将音频特征映射到模型的潜在空间,在像素级别上进行嵌入,让音频特征更自然地影响全身动作的生成,提高唇部同步的精度和全身动作的自然度。
- LoRA训练方法:基于低秩适应(LoRA)技术对预训练模型进行微调。基于在模型的权重矩阵中引入低秩分解,减少训练参数的数量,同时保留模型的原始能力,提高训练效率和生成质量。
- 长视频生成策略:为生成长视频,OmniAvatar基于参考图像嵌入和帧重叠策略。参考图像嵌入确保视频中人物身份的一致性,帧重叠保证视频在时间上的连贯性,避免动作的突变。
- 基于扩散模型的视频生成:基于扩散模型(Diffusion Models)作为基础架构,逐步去除噪声生成视频。这模型能生成高质量的视频内容,且在处理长序列数据时表现出色。
- Transformer架构:在扩散模型的基础上,引入Transformer架构更好地捕捉视频中的长期依赖关系和语义一致性,进一步提升生成视频的质量和连贯性。
OmniAvatar的项目地址
- 项目官网:https://omni-avatar.github.io/
- GitHub仓库:https://github.com/Omni-Avatar/OmniAvatar
- HuggingFace模型库:https://huggingface.co/OmniAvatar/OmniAvatar-14B
- arXiv技术论文:https://arxiv.org/pdf/2506.18866
OmniAvatar的应用场景
- 虚拟内容制作:用在生成播客、视频博主等的虚拟形象,降低制作成本,丰富内容表现形式。
- 互动社交平台:在虚拟社交场景中,为用户提供个性化的虚拟形象,实现自然的动作和表情互动。
- 教育培训领域:生成虚拟教师形象,基于音频输入讲解教学内容,提高教学的趣味性和吸引力。
- 广告营销领域:生成虚拟代言人形象,根据品牌需求定制形象和动作,实现精准的广告宣传。
- 游戏与虚拟现实:快速生成具有自然动作和表情的虚拟游戏角色,丰富游戏内容,提升虚拟现实体验的逼真度。
相关文章
AI应用官网收录了国内外数百个AI工具,该导航网站包括AI写作工具、AI图像生成、AI视频制作、AI音频转录、AI辅助编程、AI音乐生成、AI绘画设计、AI对话聊天等AI应用大全,以及AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务 Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。PS:本站数据由软件自动抓取于互联网公开信息,如有侵权,请联系qq1982182219删除