Qwen3-30B-A3B-Instruct-2507是什么
Qwen3-30B-A3B-Instruct-2507 是阿里通义开源的Qwen3-30B-A3B非思考模式语言模型,总参数量达305亿,激活参数为33亿,具备48层结构和262,144的上下文长度。模型在指令遵循、逻辑推理、多语言知识覆盖等方面表现出色,尤其适合本地部署,对硬件要求相对较低。模型支持用sglang或vllm进行高效部署,是面向开发者和研究者的强大工具,现在通过Qwen Chat可直接体验。
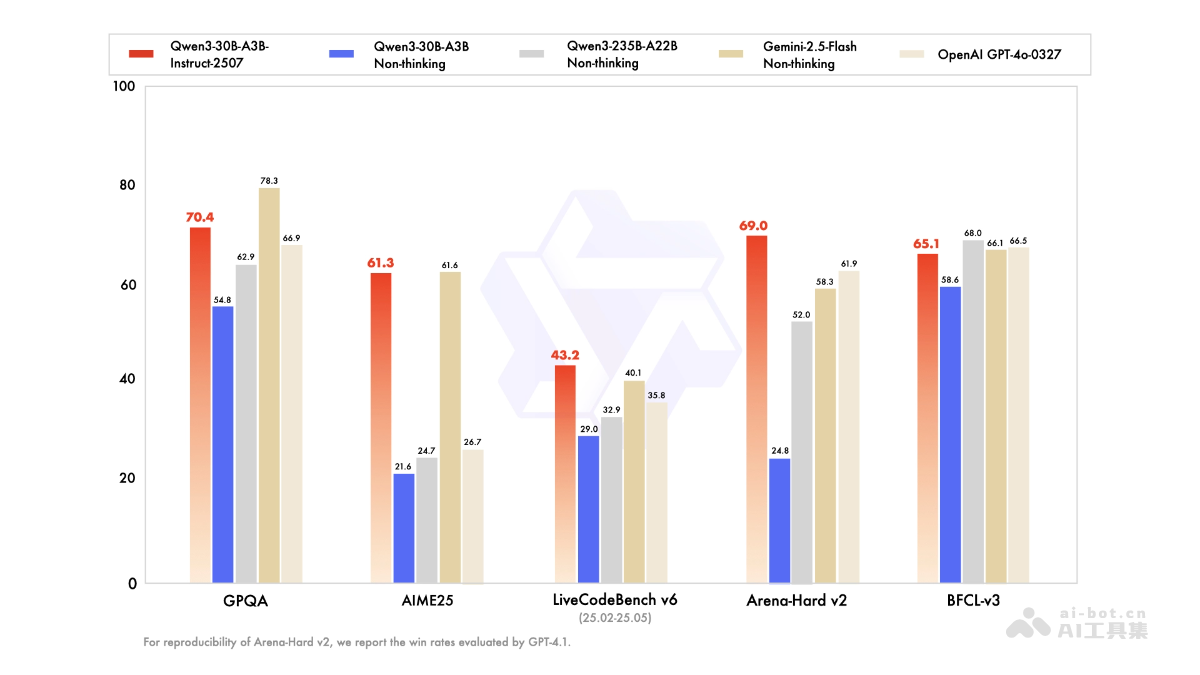
Qwen3-30B-A3B-Instruct-2507的主要功能
- 指令遵循:能准确理解和执行用户输入的指令,生成符合要求的文本输出。
- 逻辑推理:具备较强的逻辑推理能力,支持处理复杂的逻辑问题和推理任务。
- 文本理解与生成:能理解和生成高质量的文本内容,适用于多种自然语言处理任务,如写作、翻译、问答等。
- 数学与科学问题解答:在数学和科学问题上表现出色,能进行复杂的计算和推理。
- 编码能力:支持代码生成和编程任务,帮助开发者快速实现编程需求。
- 多语言支持:覆盖多种语言,具备良好的跨语言理解和生成能力。
- 长文本处理:支持262,144的上下文长度,能处理长文本输入和生成任务。
- 工具调用:基于Qwen-Agent,支持调用外部工具,增强模型的实用性。
Qwen3-30B-A3B-Instruct-2507的技术原理
- 混合专家模型(MoE):模型总参数量为305亿,激活参数为33亿。通过稀疏激活机制,在保持模型性能的同时,降低计算和内存需求。模型包含128个专家,每次激活8个专家,让模型根据输入动态选择最合适的专家进行计算,提高了效率和灵活性。
- 因果语言模型(Causal Language Model):模型基于Transformer架构,包含48层,每层有32个查询头(Q)和4个键值头(KV),让模型能有效处理长序列输入。支持262,144的上下文长度,能处理长文本输入和生成任务,适用需要长上下文理解的场景。
- 预训练:模型在大规模文本数据上进行预训练,学习语言的通用特征和模式。
- 后训练:在预训练的基础上,基于特定任务的数据进行微调,进一步提升模型在特定任务上的性能。
Qwen3-30B-A3B-Instruct-2507的项目地址
- HuggingFace模型库:https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507
Qwen3-30B-A3B-Instruct-2507的应用场景
- 写作辅助:帮助作家和内容创作者快速生成高质量的文本内容,提升写作效率。
- 智能客服:构建智能客服系统,自动回答客户咨询,提高客户满意度和响应速度。
- 编程辅助:为开发者生成代码片段、优化建议和API文档,提升开发效率和代码质量。
- 教育辅导:为学生提供学科问题解答和学习辅导,辅助教师生成教学材料和练习题。
- 多语言翻译:支持多种语言之间的翻译任务,促进跨语言交流和国际化内容生成。
相关文章
AI应用官网收录了国内外数百个AI工具,该导航网站包括AI写作工具、AI图像生成、AI视频制作、AI音频转录、AI辅助编程、AI音乐生成、AI绘画设计、AI对话聊天等AI应用大全,以及AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务 Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。PS:本站数据由软件自动抓取于互联网公开信息,如有侵权,请联系qq1982182219删除