SRPO是什么
SRPO(Semantic Relative Preference Optimization)是腾讯混元推出的文本到图像生成模型,通过将奖励信号设计为文本条件信号,实现对奖励的在线调整,减少对离线奖励微调的依赖。SRPO引入Direct-Align技术,通过预定义噪声先验直接从任何时间步恢复原始图像,避免在后期时间步的过度优化问题。在FLUX.1.dev模型上的实验表明,SRPO能显著提升生成图像的人类评估真实感和审美质量,且训练效率极高,仅需10分钟即可完成优化。
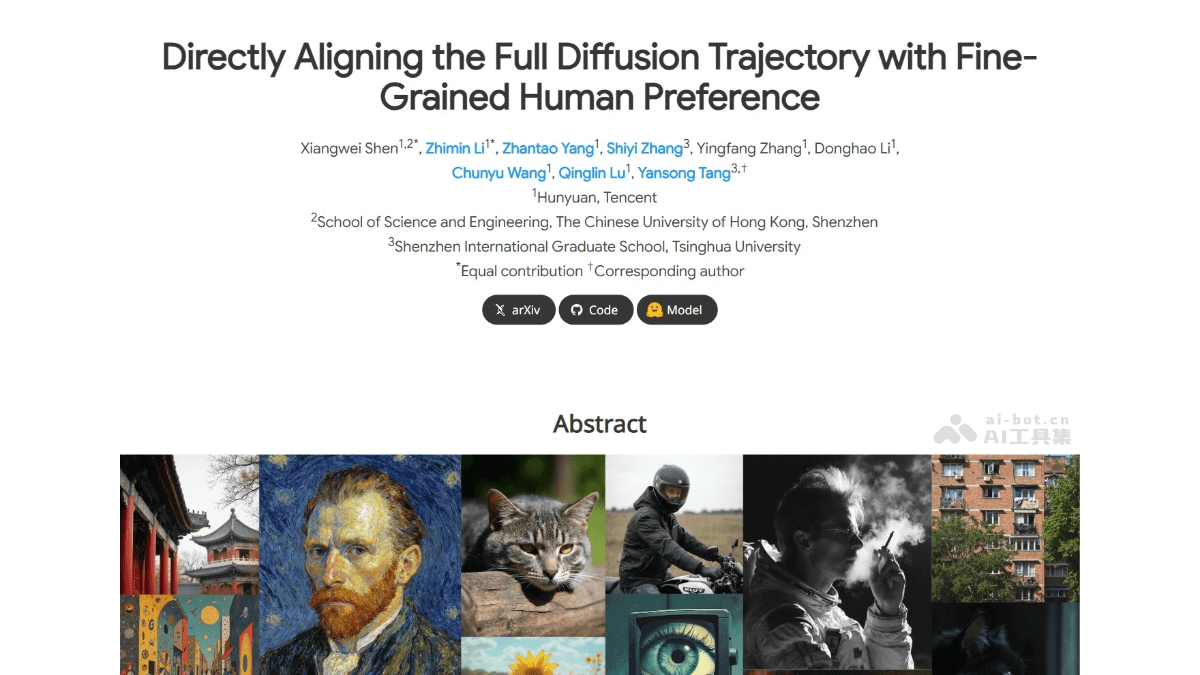
SRPO的主要功能
-
提升图像生成质量:通过优化扩散模型,使生成的图像在真实感、细节丰富度和审美质量上显著提升。
-
在线奖励调整:支持用户通过文本提示动态调整奖励信号,实时改变图像生成的风格和偏好,无需对奖励模型进行离线微调。
-
增强模型的适应性:使扩散模型能更好地适应不同的任务需求和人类偏好,例如在不同的光照条件、风格或细节层次上进行优化。
-
提高训练效率:通过优化扩散过程的早期阶段,SRPO能在短时间内(如10分钟)完成模型的训练和优化,显著提高训练效率。
SRPO的技术原理
-
Direct-Align技术:在训练过程中,SRPO向干净的图像中注入高斯噪声,通过单步去噪操作恢复原始图像。通过这种方式,SRPO能有效地避免在扩散过程的后期时间步中出现的过度优化问题,减少奖励黑客行为(如模型利用奖励模型的偏差生成低质量图像)。与传统方法相比,SRPO能在早期时间步进行优化,有助于提高训练效率和生成质量。
-
Semantic Relative Preference Optimization(SRPO):将奖励信号设计为文本条件信号,通过正负提示词对奖励信号进行调整。通过计算正负提示词对的奖励差异优化模型。SRPO支持在训练过程中动态调整奖励信号,使模型根据不同的任务需求实时调整生成策略。
-
奖励聚合框架:为提高优化的稳定性,SRPO在训练过程中会多次注入噪声,生成一系列中间图像,对每个图像进行去噪和恢复操作。通过使用衰减折扣因子对中间奖励进行聚合,SRPO能有效地减少在后期时间步中出现的奖励黑客行为,提高生成图像的整体质量。
SRPO的项目地址
- 项目官网:https://tencent.github.io/srpo-project-page/
- GitHub仓库:https://github.com/Tencent-Hunyuan/SRPO
- HuggingFace模型库:https://huggingface.co/tencent/SRPO
- arXiv技术论文:https://arxiv.org/pdf/2509.06942v2
SRPO的应用场景
- 数字艺术创作:艺术家和设计师生成高质量的数字艺术作品,通过文本提示动态调整图像风格,实现从概念草图到最终作品的快速迭代。
- 广告与营销:广告公司生成符合特定品牌风格和市场定位的图像,快速生成多种设计选项,提高创意效率。
- 游戏开发:游戏开发者生成高质量的游戏纹理、角色设计和场景背景,提升游戏的视觉效果和玩家体验。
- 影视制作:在电影和电视剧的制作中,用在生成逼真的特效场景、背景和角色,减少后期制作的时间和成本。
- 虚拟现实(VR)和增强现实(AR):模型能生成高质量的虚拟环境和物体,提升VR和AR应用的沉浸感和真实感。
相关文章
AI应用官网收录了国内外数百个AI工具,该导航网站包括AI写作工具、AI图像生成、AI视频制作、AI音频转录、AI辅助编程、AI音乐生成、AI绘画设计、AI对话聊天等AI应用大全,以及AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务 Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。PS:本站数据由软件自动抓取于互联网公开信息,如有侵权,请联系qq1982182219删除