Stand-In是什么
Stand-In 是腾讯微信视觉团队推出的轻量级的视频生成框架,专注于生成身份保护视频。框架通过训练1%的基础模型参数,能生成高保真度、身份一致的视频,具有即插即用的特点,支持轻松集成到现有的文本到视频(T2V)模型中。Stand-In 支持多种应用场景,包括身份保留的文本到视频生成、非人类主体视频生成、风格化视频生成、视频换脸和姿势引导视频生成等,具有高效、灵活和可扩展性强的优势。
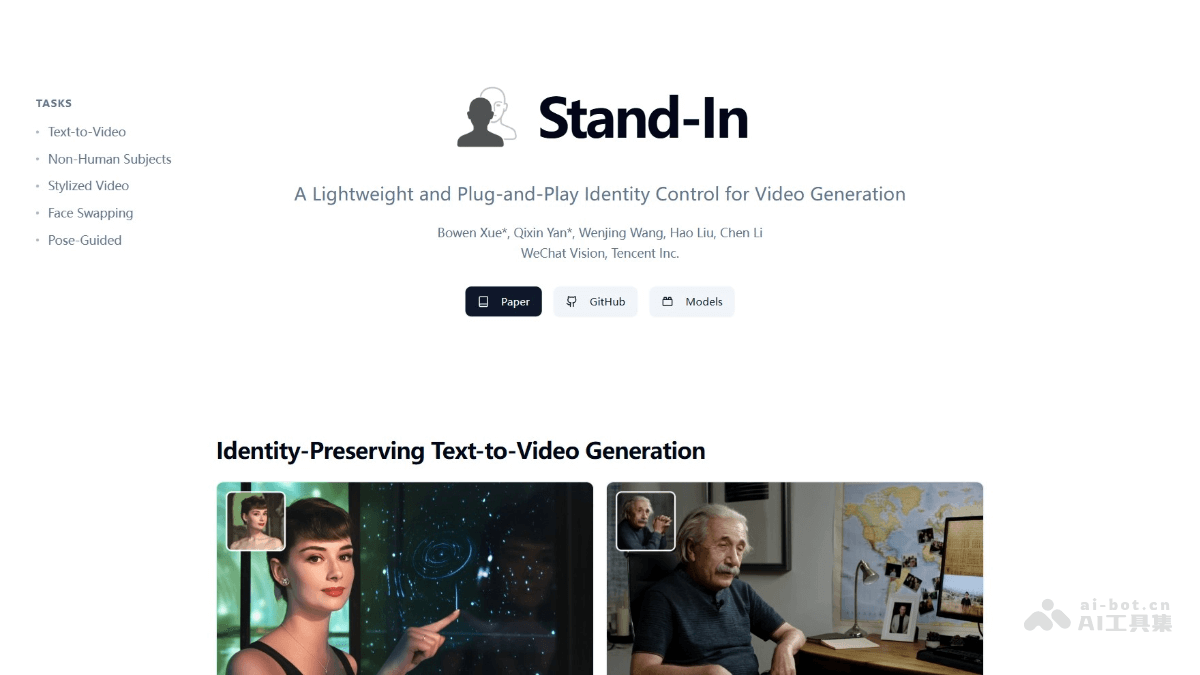
Stand-In的主要功能
-
身份保留的文本到视频生成:根据文本描述和参考图像,生成与参考图像身份一致的视频,确保人物特征在视频中保持高度一致。
-
非人类主体保留视频生成:框架能生成卡通角色、物体等非人类主体的视频,且保持主体特征的连贯性。
-
身份保留风格化视频生成:在保持人物身份特征的同时,对生成的视频应用特定的艺术风格,如油画或动漫风格,实现风格化效果。
-
视频换脸:将视频中的人物面部替换为参考图像中的面部,实现高保真度的面部替换,保持视频的自然度和连贯性。
-
姿势引导视频生成:根据输入的姿势序列,生成人物在相应姿势下的视频,实现姿势的精确控制和生成。
Stand-In的技术原理
- 条件图像分支:在预训练的视频生成模型中引入一个条件图像分支。用预训练的 VAE(变分自编码器)将参考图像编码到与视频相同的潜在空间中,提取丰富的面部特征。
- 受限自注意力机制:通过受限自注意力机制实现身份控制,支持视频特征有效地引用参考图像中的身份信息,同时保持参考图像的独立性。用条件位置映射(Conditional Position Mapping)区分图像和视频特征,确保信息交换的准确性和高效性。
- 低秩适配(LoRA):在条件图像分支中使用低秩适配(LoRA)来增强模型对身份信息的利用能力,同时保持模型的轻量级设计。LoRA 仅对条件图像的 QKV 投影进行微调,避免引入过多的训练参数。
- KV 缓存:参考图像的时间步固定为零, Key 和 Value 矩阵在扩散去噪过程中保持不变。在推理过程中缓存这些矩阵加速计算。
- 轻量级设计:Stand-In 训练约1%的额外参数,显著减少训练成本和计算资源的消耗,使 Stand-In 能轻松集成到现有的文本到视频(T2V)模型中,具有高度的可扩展性和兼容性。
Stand-In的项目地址
- 项目官网:https://www.stand-in.tech/
- GitHub仓库:https://github.com/WeChatCV/Stand-In
- HuggingFace模型库:https://huggingface.co/BowenXue/Stand-In
- arXiv技术论文:https://arxiv.org/pdf/2508.07901
Stand-In的应用场景
- 虚拟角色生成:为电影、电视剧和动画创建虚拟角色,确保角色在不同场景中的身份一致性。
- 特效合成:在特效制作中,快速生成与真人演员身份一致的虚拟角色,减少后期合成的复杂性。
- 个性化广告:根据用户提供的参考图像生成个性化的广告视频,提高广告的吸引力和用户参与度。
- 虚拟代言人:创建虚拟代言人,用在品牌推广和产品宣传,确保品牌形象的一致性和连贯性。
- 角色定制:玩家根据自己的形象生成游戏中的角色,增强游戏的沉浸感和个性化体验。
相关文章
AI应用官网收录了国内外数百个AI工具,该导航网站包括AI写作工具、AI图像生成、AI视频制作、AI音频转录、AI辅助编程、AI音乐生成、AI绘画设计、AI对话聊天等AI应用大全,以及AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务 Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。PS:本站数据由软件自动抓取于互联网公开信息,如有侵权,请联系qq1982182219删除