4D-LRM是什么
4D-LRM(Large Space-Time Reconstruction Model)是Adobe研究公司、密歇根大学等机构的研究人员共同推出的新型4D重建模型。模型能基于稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。模型基于Transformer的架构,预测每个像素的4D高斯原语,实现空间和时间的统一表示,具有高效性和强大的泛化能力。4D-LRM在多种相机设置下均展现出良好的性能,尤其在交替的规范视图和帧插值设置下,模型能有效地插值时间生成高质量的重建结果。
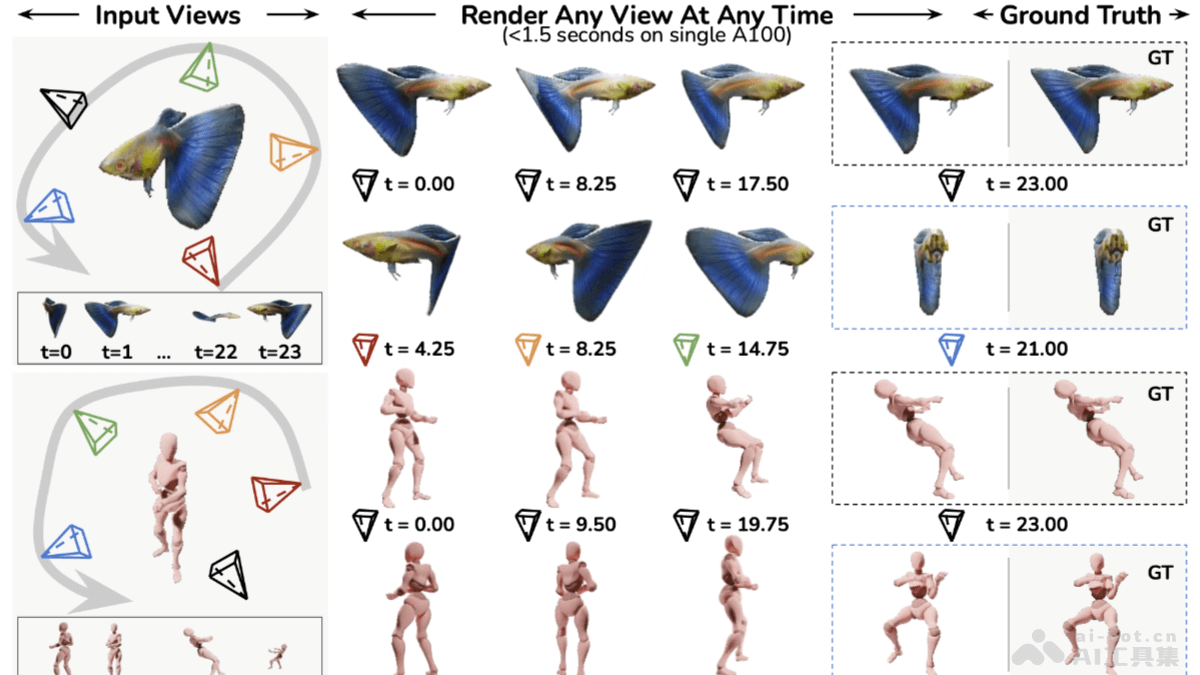
4D-LRM的主要功能
- 高效4D重建:4D-LRM能从稀疏的输入视图和任意时间点,快速、高质量地重建出任意新视图和时间组合的动态场景。在单个A100 GPU上,能在不到1.5秒的时间内重建24帧序列,展现高效性和可扩展性。
- 强大的泛化能力:支持泛化到新的对象和场景。模型在多种相机设置下均展现出良好的性能,尤其在交替的规范视图和帧插值设置下,模型能有效地插值时间生成高质量的重建结果。
- 支持任意视图和时间组合:支持生成任意视图和时间组合的动态场景,为动态场景的理解和生成提供新的可能性。
- 应用广泛:支持扩展到4D生成任务,基于与SV3D等模型结合,生成具有更高保真度的4D内容。
4D-LRM的技术原理
- 4D高斯表示(4DGS):4D-LRM将动态场景中的每个对象表示为一组4D高斯分布。高斯分布能捕捉对象的空间位置和外观,还能捕捉在时间上的变化。每个4D高斯分布由空间中心、时间中心、空间尺度、时间尺度、旋转矩阵和颜色等参数定义。
- Transformer架构:4D-LRM基于Transformer的架构处理输入图像。输入图像首被分割成图像块(patch),图像块被编码为多维向量,作为Transformer的输入。Transformer基于多头自注意力机制和多层感知机(MLP)处理输入,最终预测出每个像素的4D高斯原语。
- 像素对齐的高斯渲染:4D-LRM用像素对齐的高斯渲染技术,将预测的4D高斯分布投影到图像平面上,基于alpha混合来合成最终的图像。
- 训练和优化:4D-LRM在大规模数据集上进行训练,基于最小化重建图像与真实图像之间的差异优化模型参数。训练过程中,模型学习到的通用空间-时间表示使其能够泛化到新的对象和场景,在稀疏输入条件下生成高质量的重建结果。
4D-LRM的项目地址
- 项目官网:https://4dlrm.github.io/
- GitHub仓库:https://github.com/Mars-tin/4D-LRM
- HuggingFace模型库:https://huggingface.co/papers/2506.18890
- arXiv技术论文:https://arxiv.org/pdf/2506.18890
4D-LRM的应用场景
- 视频游戏和电影制作:高效重建和渲染动态场景,适用角色动画、场景变化等复杂场景的建模,显著提升游戏和电影的视觉效果,支持实时渲染和多视角生成,增强观众的沉浸感。
- 增强现实(AR)和虚拟现实(VR):为AR和VR应用提供真实、沉浸式的体验,支持实时交互,用户在虚拟环境中自由移动和观察。
- 机器人和自动驾驶:帮助机器人和自动驾驶系统更好地理解和预测环境变化,提供准确的路径规划信息。
- 数字内容创作:减少手动建模和动画制作的工作量,用在视频编辑,提供丰富的编辑选项。
- 科学研究:用在重建和分析生物医学成像数据,如心脏跳动、呼吸运动等,帮助研究人员理解生物体内的动态过程。
相关文章
AI应用官网收录了国内外数百个AI工具,该导航网站包括AI写作工具、AI图像生成、AI视频制作、AI音频转录、AI辅助编程、AI音乐生成、AI绘画设计、AI对话聊天等AI应用大全,以及AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务 Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。PS:本站数据由软件自动抓取于互联网公开信息,如有侵权,请联系qq1982182219删除