VLN-R1是什么
VLN-R1是香港大学和上海人工智能实验室联合推出的全新具身智能框架,基于大型视觉语言模型(LVLM)直接将第一人称视频流转换为连续的导航动作。框架基于Habitat 3D模拟器构建VLN-Ego数据集,用长短期记忆采样策略平衡历史和当前观测。框架训练分为两阶段,监督微调(SFT)让模型动作序列文本预测与专家演示对齐,强化微调(RFT)基于时间衰减奖励(TDR)机制优化多步未来动作。VLN-R1在VLN-CE基准测试中表现强劲,证明LVLM在具身导航中的有效性,提升任务特定推理能力,且数据效率高。
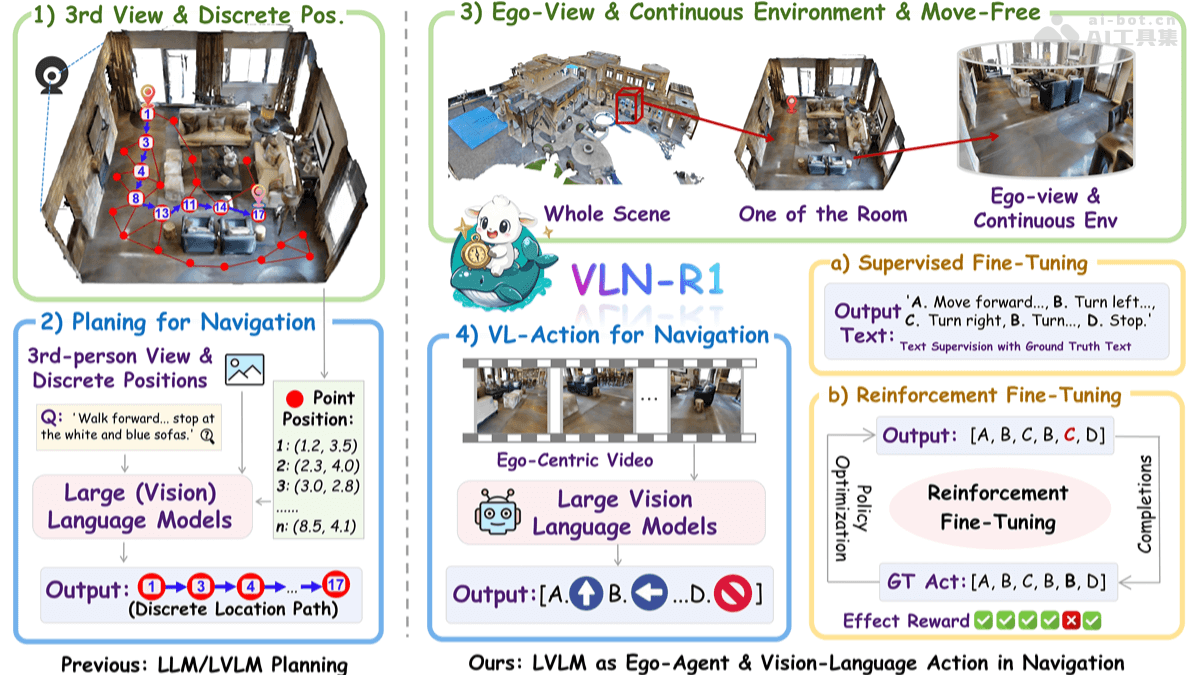
VLN-R1的主要功能
- 连续环境导航:直接处理第一人称视频流,让智能体在连续的3D环境中自由移动,不仅仅局限于预定义的节点。
- 动作生成:生成四种基本动作命令(FORWARD、TURN-LEFT、TURN-RIGHT、STOP),实现精确的导航控制。
- 数据高效训练:基于监督微调(SFT)和强化微调(RFT),用有限的数据实现高效的模型训练,提升导航性能。
- 跨领域适应:基于强化微调(RFT),模型能快速适应新的导航任务和环境,即使只有少量数据。
- 任务特定推理:基于时间衰减奖励(TDR)机制,优化多步未来动作的预测,增强长期导航性能。
VLN-R1的技术原理
- 数据集构建:VLN-Ego数据集基于Habitat 3D模拟器生成,包含第一人称视频流和对应的未来动作预测,为模型训练提供丰富的数据。
- 长短期记忆采样:在处理视频输入时,用长短期记忆采样策略,动态平衡历史帧的重要性与实时输入的敏感性,确保模型在导航过程中既考虑短期相关性,又不丢失长期上下文信息。
- 监督微调(SFT):基于最小化模型预测文本与专家演示文本之间的交叉熵损失,让模型的动作序列预测与真实动作对齐,确保模型能准确理解语言指令生成相应的动作。
- 强化微调(RFT):基于组相对策略优化(GRPO)的强化学习方法,用时间衰减奖励(TDR)机制评估和优化多步未来动作的预测,增强模型在长期导航任务中的性能。
- 大型视觉语言模型(LVLM):基于先进的LVLM(如Qwen2-VL)处理视觉和语言输入,实现从第一人称视频流到导航动作的直接映射,提升模型的泛化能力和适应性。
VLN-R1的项目地址
- 项目官网:https://vlnr1.github.io/
- GitHub仓库:https://github.com/Qi-Zhangyang/GPT4Scene-and-VLN-R1
- arXiv技术论文:https://arxiv.org/pdf/2506.17221
VLN-R1的应用场景
- 家庭服务机器人:让家庭服务机器人根据主人的自然语言指令在家中自由导航,完成打扫卫生、取物等任务,提升生活便利性。
- 工业自动化:在工厂车间助力机器人按操作员指令灵活导航,完成物料搬运和设备维护,提高生产效率。
- 智能仓储:让仓库机器人依据指令在货架间精准导航,高效完成货物存储与检索,优化仓储管理。
- 医疗保健:支持医院或养老院机器人按医护人员或患者指令导航,完成送药、送餐等任务,减轻医护负担。
- 智能交通:帮助自动驾驶车辆在复杂城市环境中按交通信号和指令导航,增强行驶安全性和灵活性。
相关文章
AI应用官网收录了国内外数百个AI工具,该导航网站包括AI写作工具、AI图像生成、AI视频制作、AI音频转录、AI辅助编程、AI音乐生成、AI绘画设计、AI对话聊天等AI应用大全,以及AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务 Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。PS:本站数据由软件自动抓取于互联网公开信息,如有侵权,请联系qq1982182219删除